

Math insists that a+b-c=a-c+b, and we take this as an unshakable truth. But in computer science, when floating-point arithmetic enters the picture, even basic rules like this can fall apart. Most developers never notice these quirks in everyday applications — but in the early days of building our Streaming SQL engine, this tiny mathematical inconsistency snowballed into a nightmarish bug. It wasn’t just hard to fix; it was hard to even understand. Let’s dive into the depths of this floating-point horror story together.
How Epsio Stores Result Data
Before we go into the inherent issues with floating arithmetic, let’s talk about how Epsio stores the result data. In Epsio, you define a “view”, which consists of two parts: a name for a result table (this will be a table Epsio creates in your database, say a Postgres database), and a query you want Epsio to maintain. Epsio will populate the result table with the answer of the query, and then continuously update it as new changes come in via the replication stream from the database. A streaming SQL engine keeps queries’ results up to date without ever having to recalculate them, even as the underlying data changes.
To make this more understandable, let’s say we had a farm with livestock, and wanted to give the animals on the farm their fair portion of the profits (trying to avoid an Animal Farm here). To know how much total salary we’ve given each animal group, we’d have a query <code-highlight> SELECT animal, sum(salary) FROM animals GROUP BY animal <code-highlight> . Because the underlying data is always changing (animals being born, asking for raises, etc) we create a simple Epsio view in our Postgres:
This would create a table in our Postgres called animal_salaries, which Epsio would continuously update with the ever changing animal salaries.
It might look something like this:

You may wonder what that “epsio_id” column is doing there, since we only ever defined two columns in our query. Epsio automatically adds another column to every result table in order to allow for efficient deleting. Internally, Epsio has a sort of “dictionary” mapping the entire row to it’s corresponding epsio id (this is actually held in RocksDB).
In our case, it would look something like this:
Bunnies,720.32:999
Pigs,7049.41:238
Let’s say all the Bunnies died (someone nefarious ran <code-highlight>DELETE FROM animals WHERE animal='bunny')<code-highlight> , and Epsio wanted to remove the bunnies row. It would find the corresponding row in it’s key mapping (Bunnies,720.32), find the corresponding epsio_id (999), and then run a delete query on Postgres:
You may notice that salaries are not round numbers. Animals can be a bothersome folk who negotiate on the penny, which means we need to keep our salaries (and therefore the sums) as floating points.
Enter Floating Points
Floating-point numbers are a way for computers to represent real numbers; numbers that can contain decimal points. Instead of storing numbers with absolute precision, floating points use a sort of “approximation”, which allows them to be both efficient in terms of space and also quick with computations. They’re represented using three numbers: a sign (positive or negative), a “mantissa”, and an exponent. So every floating point is essentially represented as:
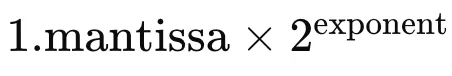
using a nifty calculator (https://observablehq.com/@benaubin/floating-point) we get:

As we can see, we’re actually not able to represent 2.4 exactly in 32bit floats! This might not seem to be that big an issue (you might say that 2.399999.. is awfully close) but it can lead to weird things.
Weird Things (aka Arithmetic with Floating Points)
So if we’re not able to represent numbers exactly, what happens when we add them up?
The question is how computers manage to add up floats that are written in this method. If the exponents were the same, then by the ever-respected laws of math we could just add up the mantissas, and keep the exponent. But if the exponents are not the same, we need to align one of the float’s exponents to be the same as the others. We do this by both changing the mantissa and the exponent- which means we get an ever so slightly different approximation. For example, if 3.8 is approximated to 3.79999 with exponent=1 and we aligned the exponent to 2 (and changed the mantissa correspondingly) it may be approximated to 3.800001.
If we do addition like this, math may not be associative. Imagine we add 4.6 and 3.8. Let’s say 4.6 has an exponent of 2 and is approximated to 4.60001, and 3.8 has an exponent of 1 and is approximated to 3.79999. As we said before we need to change one of the floats’ exponents, so let’s change 3.8 from its exponent of 1 to 2, making its approximation 3.800001 instead of 3.79999. If we add these numbers, we may get something very close to the “real” answer, which is 8.4. But if we now subtract 4.6 from this answer, and asked our computer “hey mr.computer is that now equal to 3.8”, our computer would say no.
3.800001 != 3.79999.
Now imagine we remove our original 3.8 (whose approximation is 3.7999) from that. We would get a number very close to zero, but not zero.
So 4.6 + 3.8 - 3.8 - 4.6 != 0 .
But… 4.6 + 3.8 — (3.8 + 4.6) does equal zero in floating point land. I’ll let you work out why.
Why does this matter in streaming SQL
In Epsio’s streaming SQL engine we have a concept of a “change”, which is the basic unit that is passed between query nodes. If you’d like to go into depth on how this works, my other blog post https://blog.epsio.io/how-to-create-a-streaming-sql-engine-96e23994e0dd explains it, but I’ll give you the short and relevant version here.
Every change has a key and a modification.
Let’s say a Llama appears out of the blue in our farm, demanding a very fair salary of 3.8$. We would represent it like this:

One of our query nodes is called a Group By node, which in our example from the beginning of the blog would be the last query node before our “final” node, mapping rows to their corresponding epsio_ids. The Group By node outputs aggregates per buckets. It does this by holding an internal mapping (in storage) between each bucket and its aggregated value. So in our example we would have

Let’s imagine we indeed passed Llamas +3.8 into the Group By node. It would look something like this:
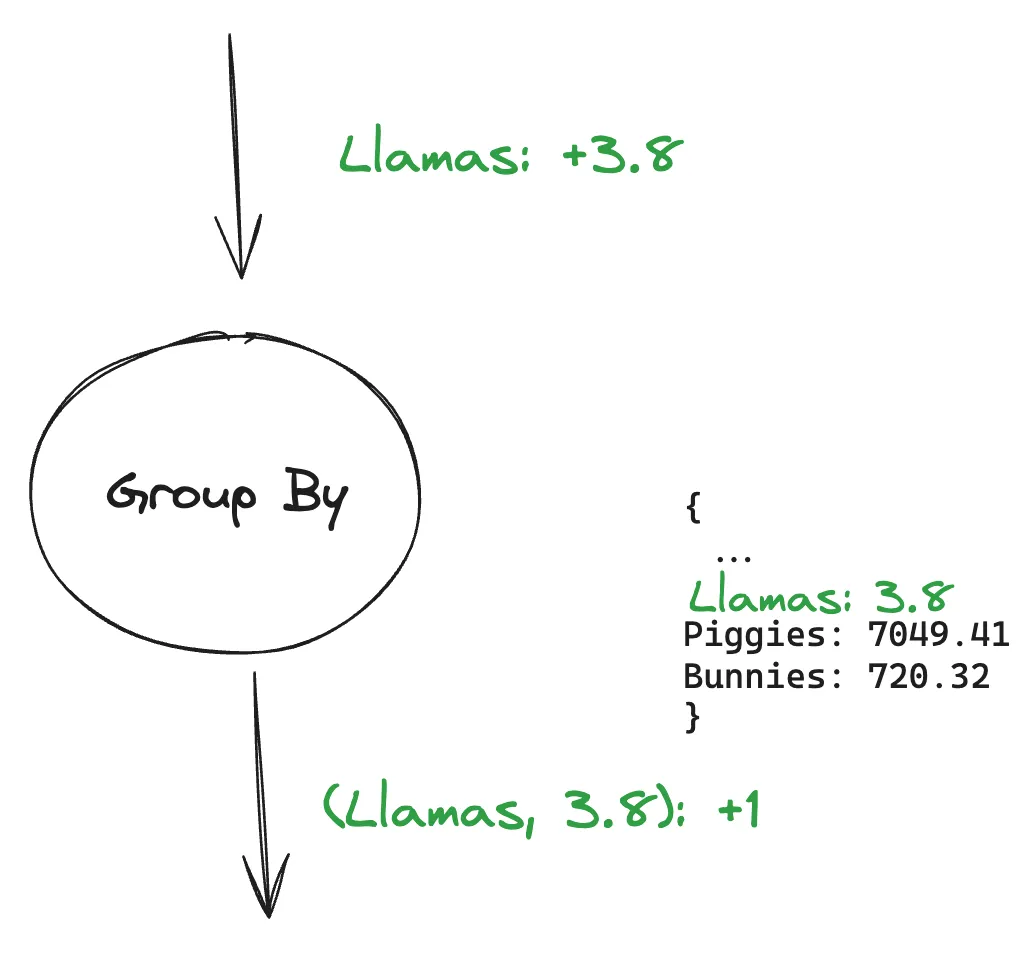
The Group By node outputs that there is now one new group (signified by the +1) of Llamas with the value 3.8.
If that Llama were to then have a Llama baby, we would have:
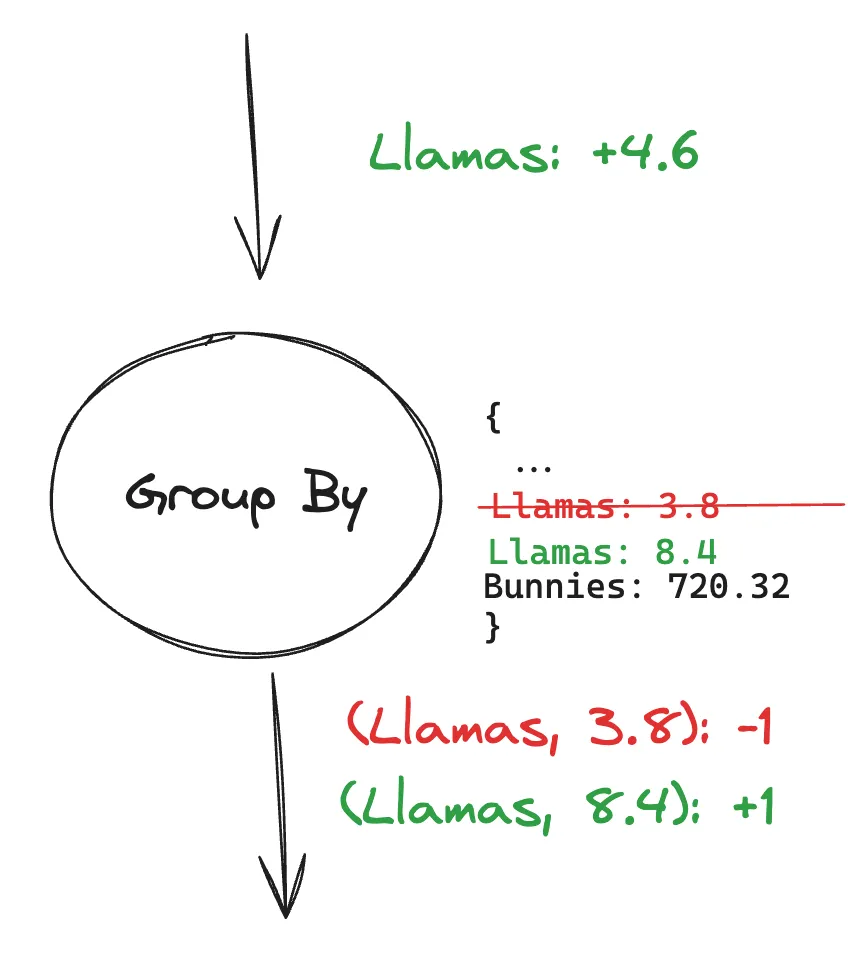
The Group By node basically tells the node after it,
“Hey, remove the row I gave you before saying (Llamas, 3.8) and create a new row called (Llamas, 8.4)”.
The Group By node always outputs a minus on what it had for the group (if the group previously existed), and a plus for the new value. Now, you might be thinking, what if both Llamas died? Wouldn’t we reach the exact scenario we talked about before where 4.6+3.8–4.6–3.8 != 0? It would be pretty weird if an end user saw that there are no Llamas in his system but Llamas receive $0.000002 of total salary.
The way Epsio solves this is by keeping track of the number of records that passed through. If the number of records from the Group By node is ever summed up to zero (e.g. we had one new record and one deletion of a record), we simply filter it out (in truth- all our aggregations are “tuples” which can have many values that we add up together at once, but that’s for another time). This is how we avoid weird situations with groups having 0.00000x values for floats.
But you might be beginning to get a feel that something weird is going on here- in a batch processing SQL engine this problem doesn’t exist as acutely, since if there are no Llamas you would never output the group. Because stream processing engines are keeping state over time, modifications that aren’t perfectly associative can cause trouble.
(Finally) The Bug
So what’s the bug?The answer lies in how our internal mappings work. We’ve previously shown our internal mapping as follows:
But how do we actually hold this data, and how do we update it?
Our keys and values are held in RocksDB, an embedded key value store. Every time we merge in a new value for a key, instead of just removing the old key and adding a new key with the updated value, RocksDB simply saves a “merge” record. So we can imagine our mappings looking something like this:

RocksDB will actually do the “merging” (in our case addition) when it either runs a process called “compaction”, or when you read a key. The thing is, RocksDB offers no guarantees on what order it’ll do the merging in. Furthermore, we have optimizations that hold some of the data in memory that we add with the result of RocksDB- this is just to emphasize the fact that there is an implicit expectation in our code that you’re allowed to “merge” records in any order you want.
This all means that we’re constantly at risk of giving off a slightly different answer- just like4.6+3.8–4.6–3.8 != (4.6+3.8)-(4.6+3.8).This rarely happens precisely because most of the time you are merging them in the same order, and so getting the same result. But nobody is guaranteeing that for you, and in rare cases you’ll run into trouble. This trouble comes in the form of telling the Final Node, which we talked about in the beginning of the blog, to delete a row that never existed. It therefore cannot find the equivalent epsio_id, and proceeds to error out.
Why this happened
In streaming engines, the concept of a modification must be extremely well defined. To us, it was anything that implements in Rust the Add trait and the Default trait- meaning both that modifications could be added together, and that they could zero out. But there was a third “trait” (not in the Rust sense) that we didn’t think too much about when building the underlying infrastructure: associativity. While “hacks” such as keeping the count (a very common solution in other SQL Engines) can seem to patch the problem, the underlying issues with associativity will come to light in other fashions. For us, the right solution was to transform floats into absolute precision numbers when they arrive at accumulative query nodes. Absolute precision means that we never have “approximations” like in floats, which guarantees us perfect associativity. The cost and overhead of having absolute precision was negligible in most situations, while engineering around them was full of pitfalls.