
.jpeg)
As part of our work at Epsio, we have the opportunity to speak with many companies trying to improve the performance of complex PostgreSQL queries running in their production systems.
Many times, we hear of companies trying to scale their instance sizes in an attempt to make their queries more performant. Usually, they expect that the bigger they make their instances, the faster their queries will run:
Although this is true many times, particularly for companies running many “simple” queries in parallel (such as retrieving a user’s past orders or fetching their email), companies with more “complex” backend queries (such as getting the 5 most purchased items in the entire system) usually find that increasing instance sizes doesn’t necessarily translate into better performance.
In this blog post, we will see how complex SQL queries scale as machine sizes increase, and try to learn where PostgreSQL doesn’t utilize its resources to their fullest potential when running analytical or complex queries :)
The Setup - TPC-H Queries
To simulate a good mix of complex queries, we used the TPC-H benchmark and ran it on various machine sizes running PostgreSQL 15 (on RDS M5 series).
The TPC-H benchmark consists of 22 queries, most of which involve many JOINs, ORDER BYs, and other operations that you would see in any other complex PostgreSQL query.
For example, Query 3 of TPC-H involves multiple JOINs, GROUP BY, and ordering:
How did we measure Query Latency?
To ensure that our results are as accurate and as helpful as possible, we simulated a production deployment. We ran all 22 queries one after another from an EC2 machine located in the same region as the RDS machine.
After running the 22 queries, we calculated the geometric mean of query latency for that machine size. We used the geometric mean instead of a regular average because it treats a 50 percent performance boost the same for all queries, regardless of their latency. You can read more about the differences here.
Attempt #1 — Default RDS configuration
On our first attempt, we ran all 22 TCP-H queries with the default RDS configuration:
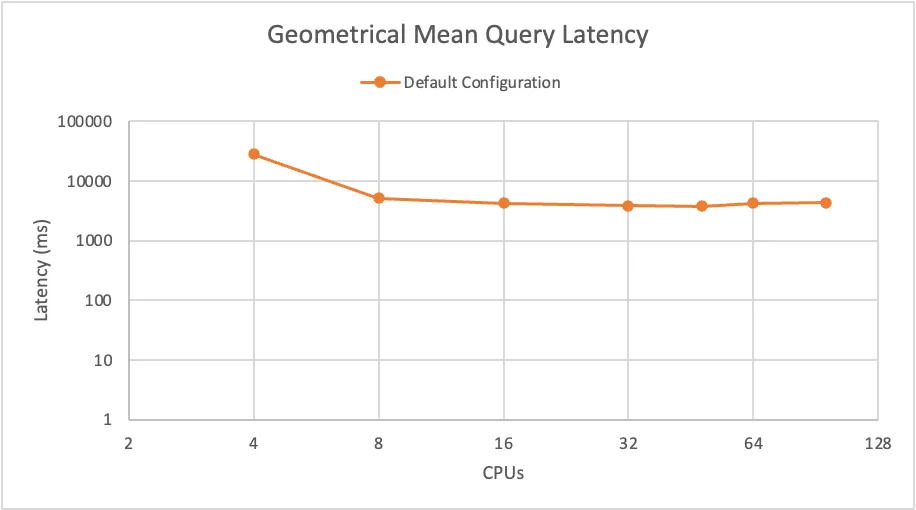
When examining the results, we could quickly see that although there was a performance boost going from 4 CPUs to 8 CPUs, there was barely any improvement increasing the machine size to more than 8 CPUs. Surprisingly, the performance even got worse going from 48 CPUs to 64 CPUs.

Since the vast majority of companies we work with already have a production deployment of more than 8 CPUs, this unfortunately means that the idea of “more compute, faster queries” does not seem to hold true with the default PostgreSQL configuration.
To try to “explain” and “analyze” this, we did what any other developer would do in this situation: we ran EXPLAIN ANALYZE (a PostgreSQL command that displays statistics and information about a query you run) on the 32 CPUs machine:
Even though our machine had 32 CPUs, PostgreSQL has chosen to launch only 2 workers (which means it used only 2 CPUs) to execute the query, utilizing only 1/16th of the available computing power! Not cool, Postgres! Just kidding, we love you.
After a quick online search (thanks pgmustard for a great blog post about configurations for parallel queries!), we discovered that this probably happened because PostgreSQL (and RDS) has a default configuration value of max_parallel_workers_per_gather set to 2.
Takeaway: Queries running on the default RDS/PostgreSQL configuration will only use up to 2 CPUs!
Onwards!
Attempt #2 — max_workers_per_gather=100
As the next step, we changed this parameter’s value to 100 and re-ran the benchmark to see how the change would affect our results:
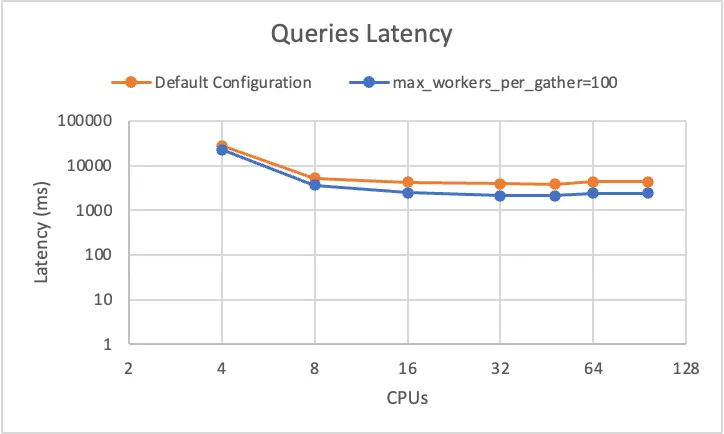
Even though the results improved, they definitely didn’t improve as we expected them to. Instead of “more compute, faster queries”, it was still “more compute, kind of the same performance”.
To try explaining and analyzing this (yes, I used the same joke twice), we ran EXPLAIN ANALYZE, and were surprised to discover that PostgreSQL had still not fully utilized it’s resources and used only 7 workers for our complex query:
Although we had additional configurations we could tinker with to “politely” ask PostgreSQL to make more use of its resources, we are not known to be “polite” people and decided to get dirty and use an “unconventional weapon”.
Attempt #3 — SET (parallel_workers = …)
To try to force PostgreSQL to use all its CPUs for our queries (with the hope that it will make them faster), we decided that a good next step would be to use [.code]ALTER TABLE table_name SET (parallel_workers=…);[.code] This configuration forces PostgreSQL to use as many parallel workers as you tell it to when accessing a table.
Obviously, this configuration is not recommended for production deployments as it forces PostgreSQL to spin up many workers even for the simplest operation on that table, leading to significant resources being consumed for every simple operation.
We configured parallel_workers to match the number of CPUs on each machine had, ran the benchmark, and……..

Barely anything changed.
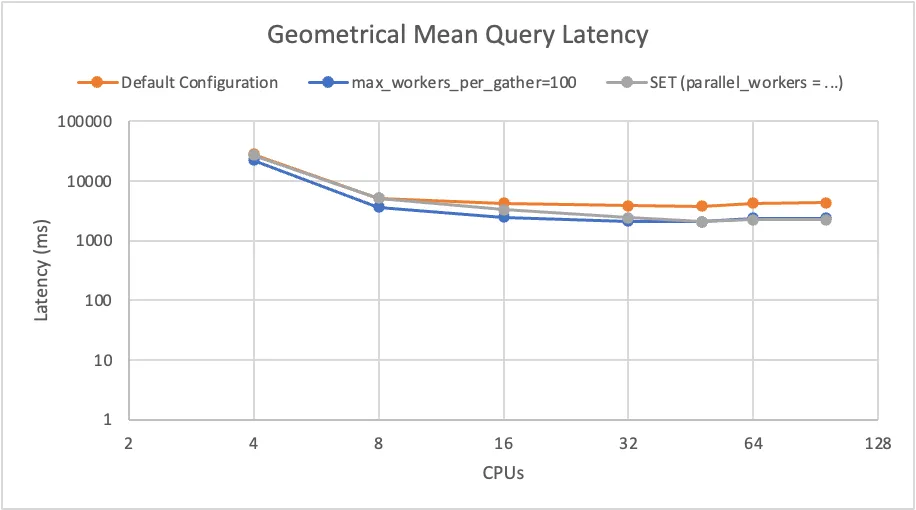
Funnily enough — this configuration seemed to not only not help, but also to increase the latency on the 16 CPUs machine.
So — why don’t queries get faster with more resources?
For those of you who are expecting to soon find the reason we discovered why PostgreSQL didn’t scale well, I wouldn’t get your hopes up. After analyzing the query plan of all 22 TPC-H queries, reading online about the subject, and asking people we trust in the field, it seems that there is not just one big reason why PostgreSQL can’t parallelize these queries efficiently. Looking back, this makes a lot of sense since if there were only one reason, the PostgreSQL community would probably just fix it.
Scaling and parallelizing queries properly is no easy task for a database, especially for one primarily built for a completely different use case (simple transactional queries). Although PostgreSQL has made amazing progress in recent years supporting workloads like the one we tested (until 2016, PostgreSQL didn’t have parallel query execution at all), there still seem to be many small and incremental changes that will need to occur before PostgreSQL can properly scale these workloads.
Having said this, while looking at the TPC-H queries, we have still noticed a couple of specific scenarios where there was an “obvious” reason why PostgreSQL did not get faster with more resources. You might want to know these scenarios so that you can avoid them in the future when trying to optimize a query.
#1 — CTEs & Sub-Queries can sometimes cause only a part of the query to run in parallel
Although it is not always the case (depending on the specific logic written in them), many times CTEs, scalar subqueries, or even normal subqueries will not run the outer part of the query in parallel.
While in this scenarios, a large part of the query can still run in parallel, there is a certain limit to how much a query can be optimized given there is always a part of it the won’t run in parallel (see Amdahl’s law).
For example, you can see in this TPC-H query that the PostgreSQL used 16 workers for the initial Gather, but then ran a hash join on top of the gathered result with a single worker (i.e., process):
#2 — Some operators won’t run in parallel at all
Some operators in PostgreSQL cannot run in parallel. If you use these operators, your entire query / gather operation will run on a single worker. These operators include:
- Window functions
- Some SORT operations
- Functions that are not explicitly defined as “PARALLEL SAFE”
- FORIEGN DATA WRAPPERS
Additionally, some operators / query plans can run in parallel but are less efficient in that mode, meaning PostgreSQL might choose to run the query in a single process even though it can parallelize it. For example, Joins that are using a merge join, can scan the outer set in parallel, but must scan the inner set repeatedly in every worker (as seen in this article). This means that launching 32 workers will result in scanning the full outer set 32 times (which is not very cost-effective). Therefore, the planner might choose not to parallelize it, even though it can.
TPC-H Query #13, for example, was never parallelized in our workload because it used merge join (even with the configuration forcing it to use parallel_workers):
About Epsio
Epsio is an incremental engine that plugs into existing databases and constantly updates results of complex queries you define whenever the underlying data changes, without ever needing to recalculate the entire dataset. This means Epsio can provide instant and up-to-date results for complex queries (while also reducing compute costs!).
Check out our docs, or better yet, start playing with us!